Spent the morning unlearning what I thought I knew about logits. Notes from chapter 4 of the deep learning book + a sketch I drew on the back of a napkin while waiting for k8s pods to schedule. Turns out temperature is one of those things everyone uses but few people actually sit with long enough to build intuition.
The short version
Temperature (τ) is a knob for how much you trust your model's raw outputs. High temperature = "I'm not sure, spread the probability around." Low temperature = "I'm very confident, sharpen the distribution."
That's it. That's the whole mental model. Everything else is just the math confirming this.
What softmax actually does
Before we touch temperature, let's make sure softmax is solid. Given a vector of
logits z — the raw, unnormalized outputs of a neural network — softmax
converts them to a proper probability distribution:
softmax(z_i) = exp(z_i) / Σ exp(z_j)
Every output is between 0 and 1. They all sum to 1. The exponential does the heavy lifting: it makes big logits much bigger relative to small ones, creating a natural "winner takes more" dynamic.
The subtle thing people miss: softmax doesn't just normalize. It amplifies differences. A logit of 5.0 vs 4.0 — only 1.0 apart — becomes a probability ratio of roughly 2.7:1 after exponentiation. Softmax is opinionated by default.
Enter temperature
When you introduce temperature, you divide each logit by τ before applying softmax:
softmax(z_i / τ) = exp(z_i / τ) / Σ exp(z_j / τ)
This single division changes everything about the output distribution. Let's walk through the extremes.
τ → 0 (freezing cold)
Dividing by a tiny number makes all logits huge, but the largest one dominates exponentially. The distribution collapses to a one-hot vector — pure argmax. The model becomes maximally confident, always picking its top choice with probability ≈ 1.
τ = 1 (room temperature)
No change. You get the distribution the model was trained to produce. This is the default behavior.
τ → ∞ (boiling hot)
Dividing by a massive number squashes all logits toward zero. exp(0) = 1
for everything, so the distribution approaches uniform. The model says "I genuinely
have no idea, all options are equally valid."
The key insight: temperature doesn't change what the model learned. It changes how decisively the model acts on what it learned.
Where the name comes from
The "temperature" metaphor is borrowed from statistical mechanics, specifically the Boltzmann distribution:
P(state_i) = exp(-E_i / kT) / Σ exp(-E_j / kT)
Same structure. In physics, high temperature means high entropy — particles explore more states randomly. Low temperature means particles settle into low-energy states predictably. The analogy is perfect:
- Low T → system settles into the most likely state (greedy, deterministic)
- High T → system explores many states (random, creative)
This isn't a loose metaphor. It's the exact same equation with different variable names. The logits are negative energies. The temperature scales exploration. That's it.
The napkin sketch
I drew three softmax distributions at τ=0.5, τ=1.0, and τ=2.0 over a 4-class problem
with logits [2.0, 1.0, 0.5, 0.1].
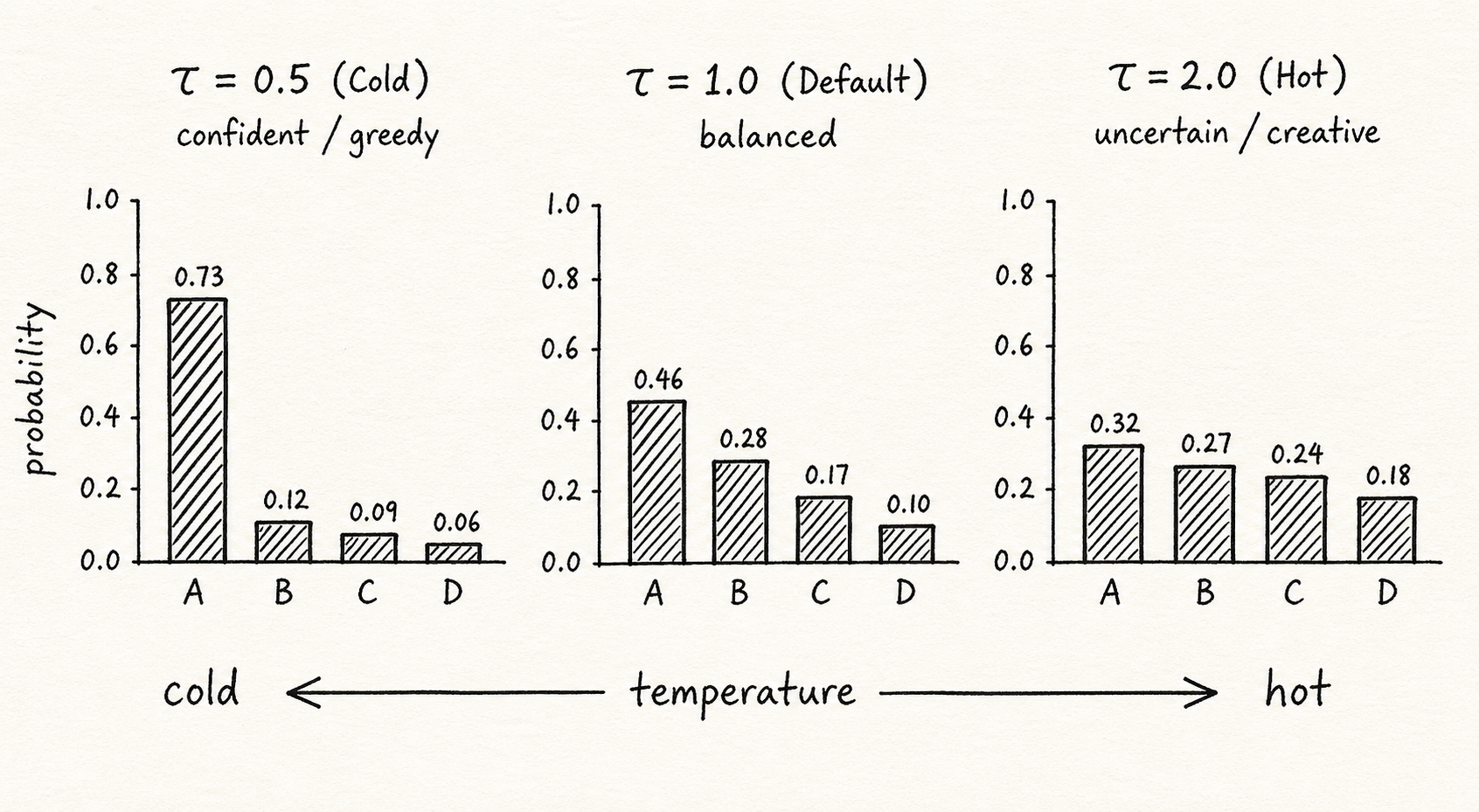
At τ=0.5, the top class gets ~73% probability. It's a spike — the model is very sure. At τ=1.0, the top class drops to ~46%. Still the winner, but not by a mile. At τ=2.0, probabilities are roughly 32%, 27%, 24%, 18%. Almost flat. The model shrugs.
The visual difference is striking. Same logits, same model, same learned knowledge. Completely different behavior.
Where you actually see this
Temperature shows up everywhere in modern ML, and knowing what it does makes a lot of API parameters suddenly make sense.
LLM text generation
When you set temperature=0.2 in the OpenAI API, you're telling the model
"be predictable, pick the most likely tokens." At temperature=1.5, you get
more creative, surprising (and sometimes unhinged) completions. It's the same model
either way — you're just turning the confidence dial.
Knowledge distillation
Hinton's distillation paper uses high temperature to "soften" a teacher model's outputs. Why? Because the relative probabilities of wrong answers carry useful information. At τ=1, the teacher might say "it's a 3" with 99% confidence. At τ=20, it might say "it's a 3 (40%) but also looks like an 8 (25%) and a 5 (15%)." That softer distribution is a richer teaching signal.
Reinforcement learning
The explore-exploit tradeoff. High temperature early in training = explore more actions. Anneal the temperature down over time = gradually commit to what works. Same principle, different domain.
Common mistakes I've seen (and made)
- Confusing temperature with top-k/top-p. Temperature reshapes the entire distribution. Top-k truncates it. Top-p clips by cumulative probability. They're different knobs — and they compose.
- Thinking τ=0 is safe. Greedy decoding (τ→0) gives you the single most likely sequence, but that's not always the best sequence. Beam search with moderate temperature often produces better results.
- Not realizing temperature is applied before sampling. The softmax distribution is computed with temperature, then you sample from that distribution. Temperature doesn't add randomness — it modulates how much randomness the existing distribution contains.
The mental model that sticks
Forget the physics metaphor if it doesn't click. Here's the one that works for me:
Temperature is how many drinks your model has had. Sober (τ→0) = rigid, by-the-book, won't take risks. Tipsy (τ=1) = normal, balanced judgment. Hammered (τ→∞) = says anything, zero filter.
Crude? Yes. Accurate? Also yes.
Takeaway
Next time someone says "adjust the temperature," just read it as "adjust the confidence." It clicks faster that way. The model already knows what it knows. Temperature just decides how boldly it acts on that knowledge.
One parameter. No retraining. Complete control over the confidence-creativity tradeoff. Pretty elegant, honestly.